While TabPFN shows great performance in certain circumstances, it does not scale well with larger datasets (quadratic memory). This paper proposes a method to improve the context given to the PFN model by using a nearest-neighbors based approach.
Approach
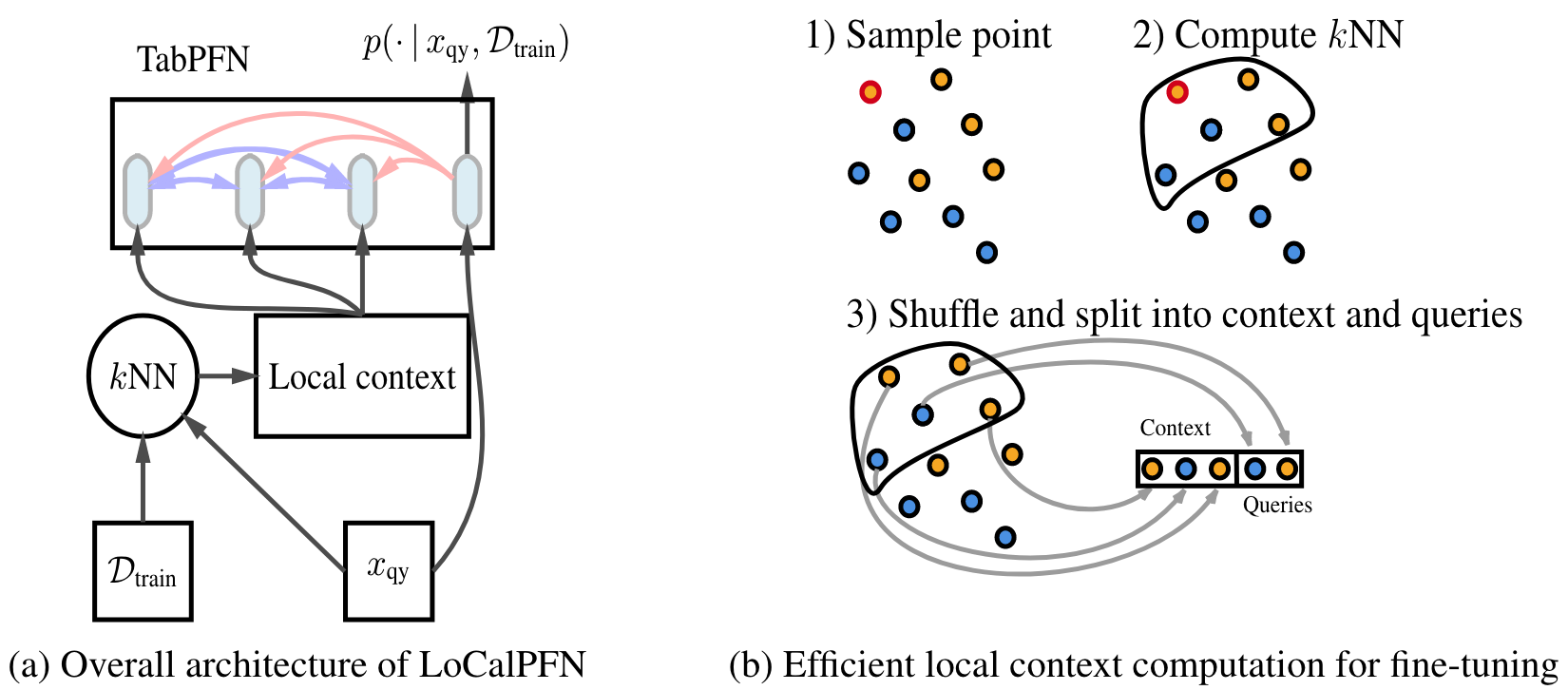
Architecture
Description of the proposed architecture.
a). Perform \(k\)NN for \(x_{\text{qy}}\) in \(\mathcal{D}_{\text{train}}\) as input to the TabPFN classifier.
b). Use approximation of \(k\)NN (pre-computed by randomly selected points) to improve efficiency.
Context from local data
Motivation
TabPFN is limited to randomly sampling the dataset when \(\mathcal{D}_{\text{train}}\) is too large. This can lead to suboptimal performance. How can we optimize the context given to the TabPFN model?
Original TabPFN classification given \(\mathcal{D}_{\text{train}} \triangleq \{(x^i_{\text{train}}, y^i_{\text{train}})\}_{i=1}^{N}\), \(x^{i}_{\text{train}} \in \mathbb{R}^D\), \(y^{i}_{\text{train}} \in \{1, ... , C\}\) and a query point \(x_{\text{qy}}\):
using \([\cdot]\) as the indexing operator and \(\mathcal{D}_{\text{context}} \triangleq \mathcal{D}_{\text{train}}\) (context is entire training dataset).
The proposed method, LoCalPFN, uses a \(k\)-nearest neighbors approach to improve the context given to the TabPFN model. Thus, \(\mathcal{D}_{\text{context}} \triangleq k\text{NN}(x_{\text{qy}})\) is now a subset of \(\mathcal{D}_{\text{train}}\).
Improving efficiency for fine-tuning
Motivation
Original TabPFN takes input of shape \((B, L_{\text{ctx}} + L_{\text{qy}}, d)\) where \(B\) is the batch size (set to 1 because there is only one context that is shared for every query point), \(L_{\text{ctx}}\) is the number of context points, \(L_{\text{qy}} = N_{\text{qy}}\) is the number of query points, and \(d\) is the dimension of the input. But if we were to apply the above approach, we need to re-compute the \(k\)NN context for each query point, meaning the input now has shape \(B = N_{\text{qy}}\), \(L_{ctx} = k\), \(L_{qy} = 1\). This can become very expensive for fine-tuning.
Instead, the authors propose to pre-compute the \(k\)NN context to approximate the exact process. If we want to fine-tune the model for \(N_{\text{qy}}\) points, we start by selecting \(B\) random points, compute their \(k\)NN context where \(k = L_{\text{ctx}} + L_{\text{qy}}\), \(L_{\text{qy}} = N_{\text{qy}} / B\), and store it. Then each \(k\)NN group can be split into query and context to fine-tune the TabPFN model. This way, we can ensure that the query points and context points are always local to each other.
Findings
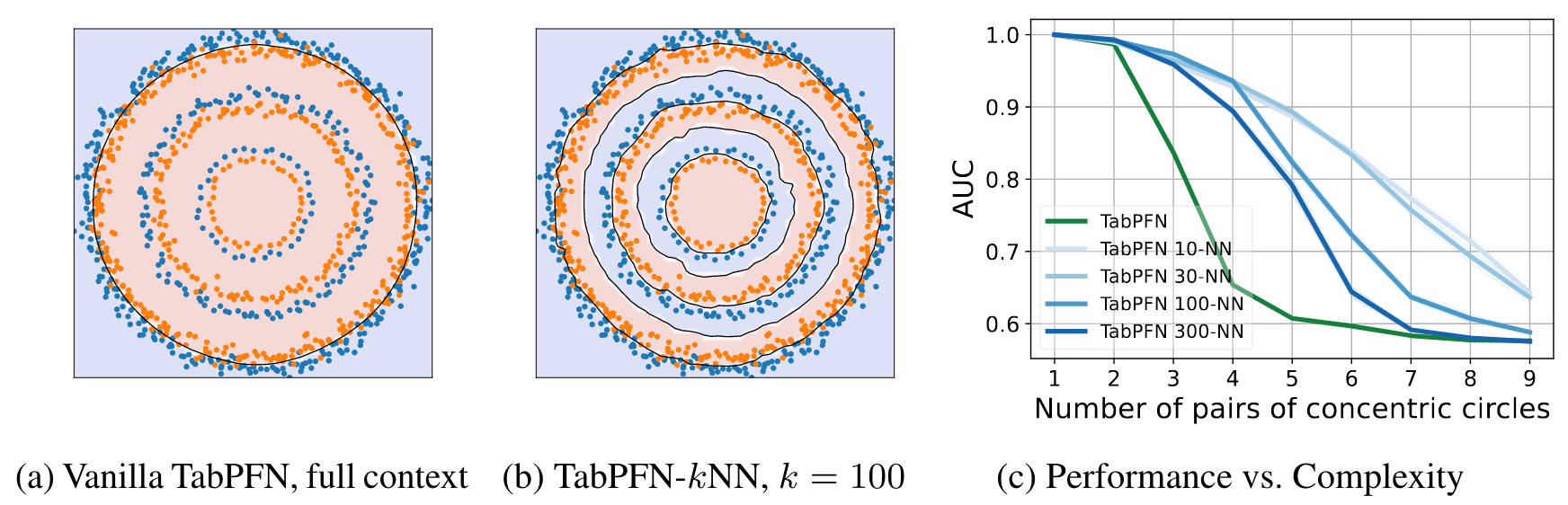
Limits of TabPFN/Benefit of local context
Comarison between TabPFN and LocalPFN on a toy dataset
a). As the complexity/size of the dataset increases, vanilla TabPFN struggles.
b). Using local context as input instead of the whole training set improves performance.
c). Performance vs. \(k\). Large \(k\) tends to "oversmooth" and suffer from high bias/underfitting, while small \(k\) enables more complex decision boundaries but can suffer from more variance/overfitting.
Experiments
Setting
96 datasets from TabZilla[^1] benchmark suite.
Main: TabPFN, TabPFN + \(k\)NN (No fine-tuning) and LocalPFN.
Dataset size/complexity
TabPFN is already quite competitive in small datasets.
But LocalPFN improves (and upon TabPFN + \(k\)NN).
LocalPFN can outperform other models in larger/more complex* datasets.
Ablations
Using both fine-tuning and \(k\)NN yields best performance.
\(k\)NN in the original space is already quite good. Using one-hot embedding further improves a bit.
But using the embeddings from the TabPFN encoder is not as good.
[!intuition]
Features values in tabular datasets can be semantically meaningful. Thus a distance metric that decomposes over individual features, i.e. \(d(x, x') = \sum_{i} d(x_i, x_i')\) can be more effective than a learned distance metric.
Using the local context is better than using the global context.
Instead of a single randomly-sampled context, compare against variations that try to use the full data for a global context.
Compared against random ensemble and ensemble with no overlap.
When not fine-tuning (TabPFN + \(k\)NN), \(k\) does not matter as much. But when fine-tuning (LocalPFN), more \(k\) can be better.