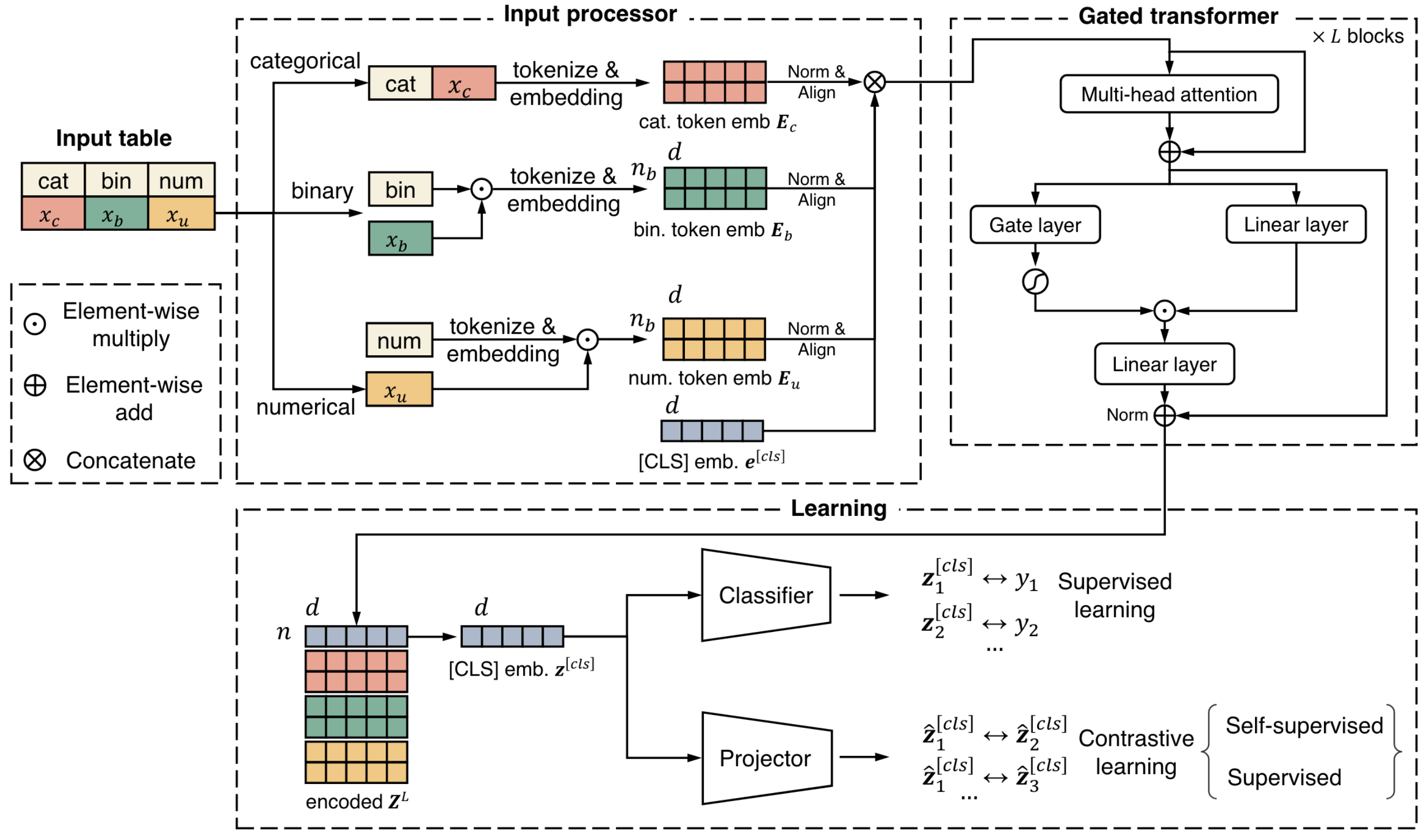
This work proposes a method to convert table rows into a sequence of token-embeddings similar to how NLP methods process text. This formulation allows for a more flexible usage of learned information from tables, such as transfer-learning, pre-train/fine-tune, incremental-learning or even zero-shot inference. This method shows superior performance compared to existing methods, and is widely adopted by following tabular works.
Approach
Overview of the approach
Input transformation
Categorical: Column name + cell value (tokenized & embedded).
Continuous: Column name (tokenized & embedded) * cell value.
Then stack everything into a sequence.
Transformer backbone
Pretty much the same as vanilla transformer, but use a GLU (gated linear unit) instead of MLP for the FFN module. For layer \(l\):
where \(\bf{g}^l = \sigma(\bf{Z}_{\text{att}}^l \bf{w}^G) \in [0,1]^n\) is a token-wise gating layer where \(\sigma\) is the sigmoid function and \(\odot\) is the element-wise product and \(\oplus\) is the element-wise addition.
Question
The authors say the gating is meant to focus on important features by redistribution the attention on tokens, but how that is actually achieved is not made very clear to me. Maybe this is just the point of the gating mechanism and I'm not getting it?
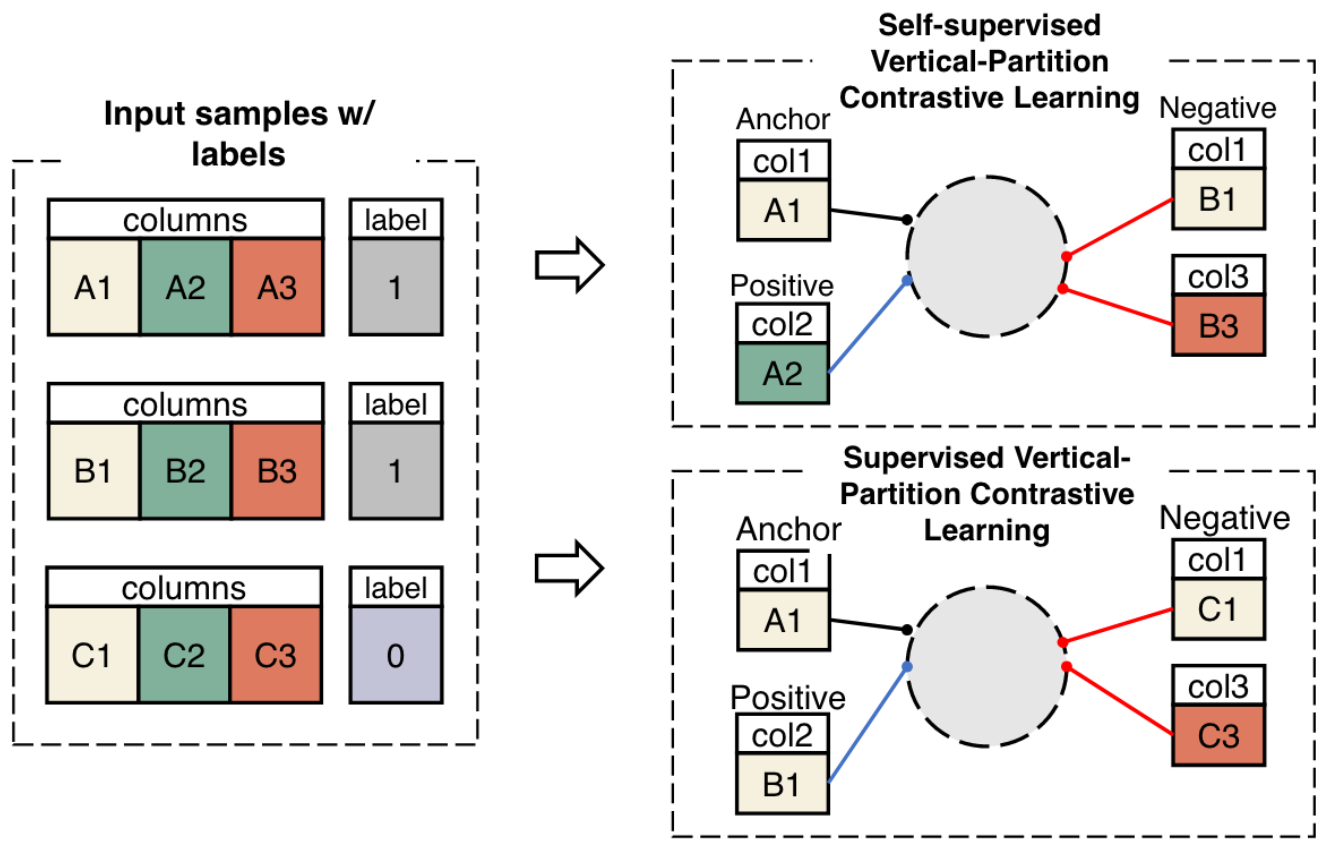
Vertical Partitioned Contrastive Learning (VPCL)
Diagram of supervised and self-supervised VPCL
Top shows the self-supervised and the bottom shows the supervised variant.
Self-Supervised VPCL
Given sample \(\bf{x}_i = \{\bf{v}_i^1, ... , \bf{v}_i^K\}\) with \(K\) partitions, use partitions from the same sample as positive and others as negative.
where \(B\) is the batch size, \(\phi\) is the cosine similarity of the [CLS] embeddings of the partitions,
Intuition
We want the similarity of partitions from the same sample to be higher (\(\exp\phi(\bf{v}_i^k, \bf{v}_i^{k'})\)), while keeping the similarity of partitions from different samples low (\(\exp \phi(\bf{v}_i^k, \bf{v}_j^{k^{\dagger}})\)). I think the authors forgot to include \(j \neq i\) when sampling the batches.
Supervised VPCL
Motivation
The authors argue that pre-training using task(dataset)-specific classifier heads with supervised loss is inadequate for transferrability, as it may cause the encoder to be biased to the major tasks and classes.
In addition, the authors propose a supervised contrastive-learning scheme inspired by Khosla et. al1, called Vertical Partitioned Contrastive Learning (VPCL).
where \(\bf{y} = \{y_i\}_i^{B}\) are batch labels and \(\mathbf{1}\{\cdot\}\) is an indicator function (so any cases that do not meet the condition are zero-ed out).
Intuition
We want the similarity of partitions with the same label to be higher (\(\exp\phi(\bf{v}_i^k, \bf{v}_j^{k'})\)), while keeping the similarity of partitions with different labels low (\(\exp \phi(\bf{v}_i^k, \bf{v}_{j^{\dagger}}^{k^{\dagger}})\)).
Findings
Vanilla supervised setting
Logistic regression is surprisingly strong.
Aside from TransTab, only FT-Transformer shows competitive performance.
TransTab is better than FT-Transformer in most cases.
Incremental columns
Setting
Where the new data includes previously unseen columns. Baselines would need to either drop the old data or ignore the new columns.
TransTab outperforms.
Transfer learning
Setting
Split datasets into two sets with some overlapping columns. Baselines can train on just one and test on it. TransTab is pre-trained on one and fine-tuned/tested on the other.
TransTab outperforms.
But not in all cases anymore! Why does XGB do better in one subset than TransTab? Is this splitting unintentionally doing some feature selection??
Zero-shot inference
Setting
Split datasets into three sets with no overlapping columns. TransTab is trained on 2 of the sets and tested on other for zero-shot. Compare with train/test on just one set and pre-train on 2 sets, fine-tune/test on last set.
Transfer shows best performance.
Somehow zero-shot is better than supervised!
Since two-sets worth of columns is more information than just one set?
VPCL vs. Vanilla supervised pre-training vs. Vanilla self-supervised pre-training
Setting
Compare against vanilla supervised, transferring with vanilla supervised, and VPCL (both self-supervised and supervised).
Self-supervised VPCL shows better performance over supervised variant when partition numbers increase.
Vanilla supervised transferring can sometimes even hurt performance (worse than just vanilla single-dataset setting).
Only on 5 datasets though.
Question
Is supervised-transfer same as "pre-training on supervised loss on other datasets"? Or is the model already pre-trained (maybe with VPCL) and is fine-tune/transferred for vanilla supervised setting?