The authors propose an in-context-learning architecture for classification on tabular data.
Approach
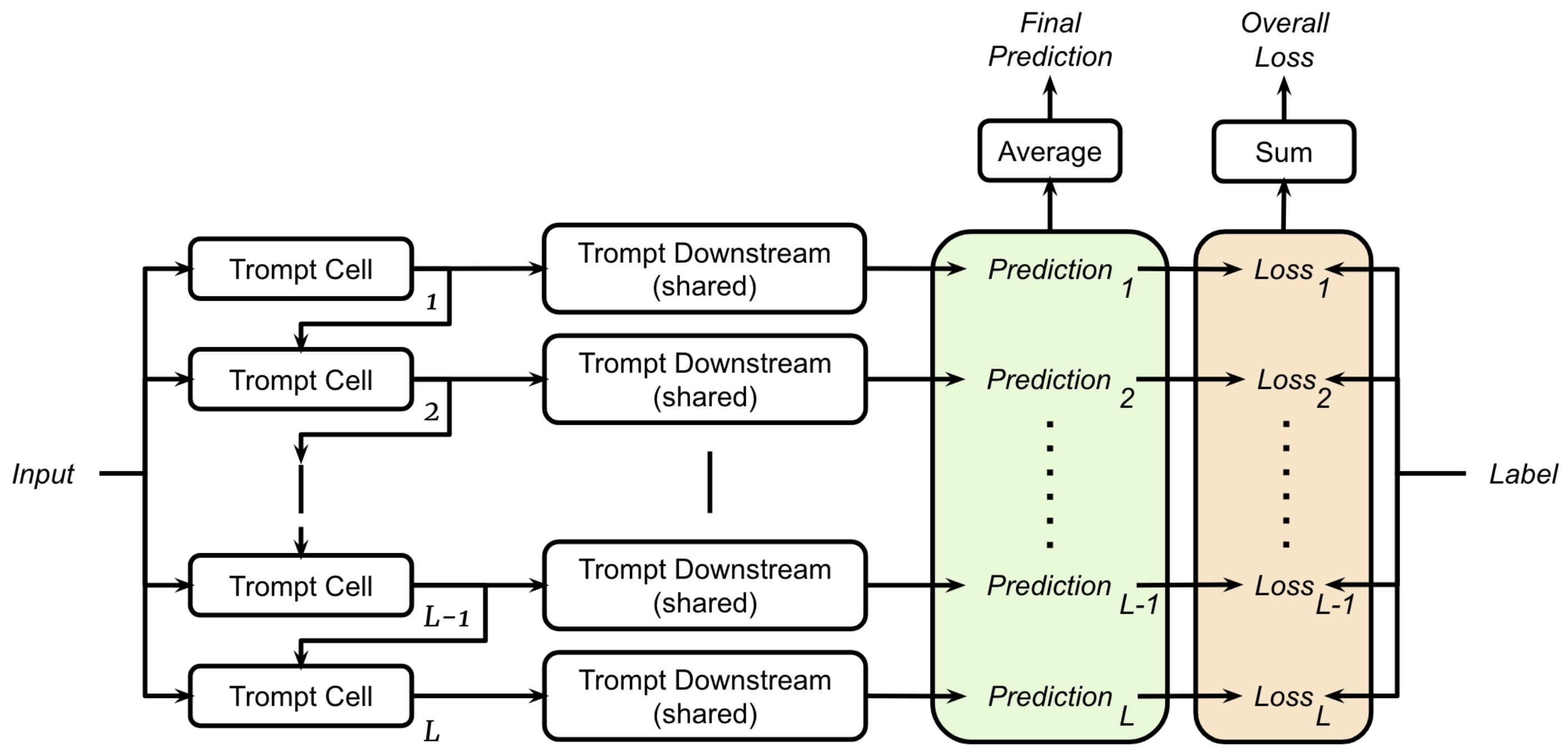
Overall architecture of Trompt
The Trompt model uses multiple Trompt Cell, each of which handles a row of a table. The \(n\)th cell receives the prompt generated by the \(n-1\)th cell.
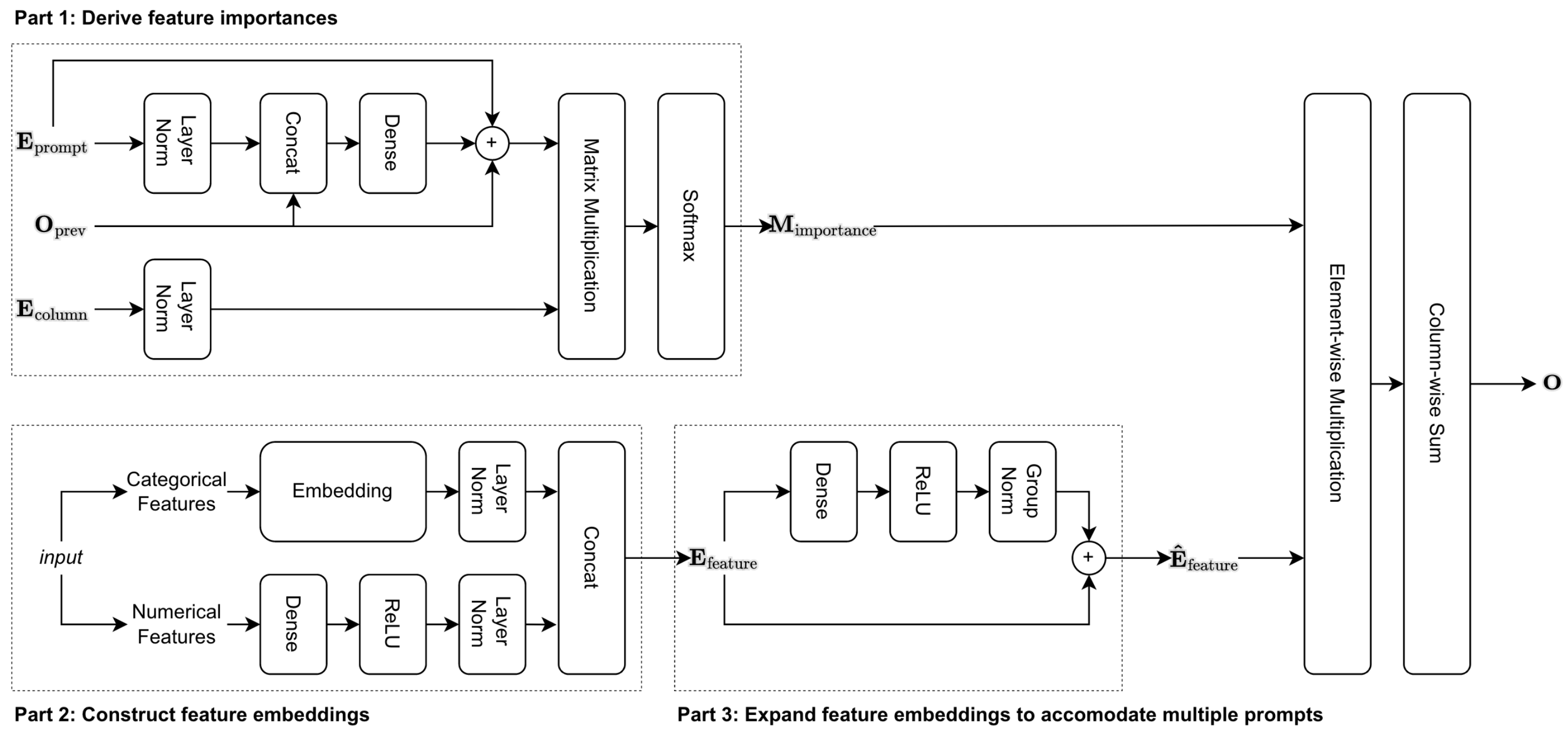
Trompt Cell
Illustration of a single Trompt cell. Part 1. shows using the previous prompt and column embeddings to generate the next prompt. Part 2 shows how actual input data is transformed, and Part 3 shows how the feature embeddings are expanded for usage with multiple prompts.
Setting
Given a table with \(N\) rows \(C\) columns, we want to learn a Trompt model that has a latent dimension of \(d\), \(L\) cells and \(P\) soft-prompts.
Part 1. Feature Importance
The feature importance scores are computed by using the column embeddings \(\mE_{\text{column}} \in \R^{C\times d}\), soft-prompts \(\mE_{\text{prompt}} \in \R^{P \times d}\) and the previous Trompt cell's output \(\mO_{\text{prev}} \in \R^{B \times P \times d}\). Note that \(\mO_{\text{prev}}\) has an extra batch dimension because the data is loaded in batches. \(\mE_{\text{column}}\) and \(\mE_{\text{prompt}}\) are expanded into \(\mS\mE_{\text{column}} \in \R^{B \times C \times d}\) and \(\mS\mE_{\text{prompt}} \in \R^{B \times P \times d}\).
The authors say that this mechanism 'enables input-related representations to flow through and derive sample-specific feature importances'. The 'flow through' part comes from the fact that the \(n\)th cell sees what the \(n-1\)th cell did. The sample-specific part comes from the fact that the prompt is generated based on the previous prompt and input sample, and not by a table-wide importance score. We can think of this as a way to map the interaction between individual prompt tokens and the table columns. In other words, \((\mM_{\text{importance}})_{i,j,k}\) should tell us the importance of interaction between the \(j\)th prompt and the \(k\)th column for sample \(i\).
Parts 2 & 3. Generating/Reshaping Feature Embeddings
Now that the per-instance feature importance scores are computed, the actual representation of the instance itself needs to be computed. This is done through a rather standard procedure12, using an embedding lookup table for categorical features and a dense layer for numerical features. This process yields \(\hat{\mE}_{\text{feature}} \in \R^{B \times C \times d}\). However, \(\hat{\mE}_{\text{feature}}\) cannot be directly used with the importance scores \(M_{\text{importance}}\) because the shapes do not match. To fix this, \(\mE_{\text{feature}}\) is transformed once more by a dense layer to turn into \(\R^{B \times P \times C \times d}\). Now we can expand \(\mM_{\text{importance}}\) into \(\R \in {B \times P \times C \times 1}\) and apply element-wise multiplication to compute the output of the Trompt layer.
For classification, a weighted sum is applied to \(\mO\) to get the input to the downstream classifier by training a dense layer to compute the weights for each prompt.
Where \(\mP\) is the prediction and \(T\) is the number of target classes.
Experiments
The authors focus on the WhyTrees benchmark3, which contains 45 datasets that were found to be difficult for both tree-based and deep learning models. Using this dataset, Trompt is compared against FT-Transformer1, SAINT2, ResNet3, XGB, LightGBM, Catboost, and Random Forest.
Findings
Main Results
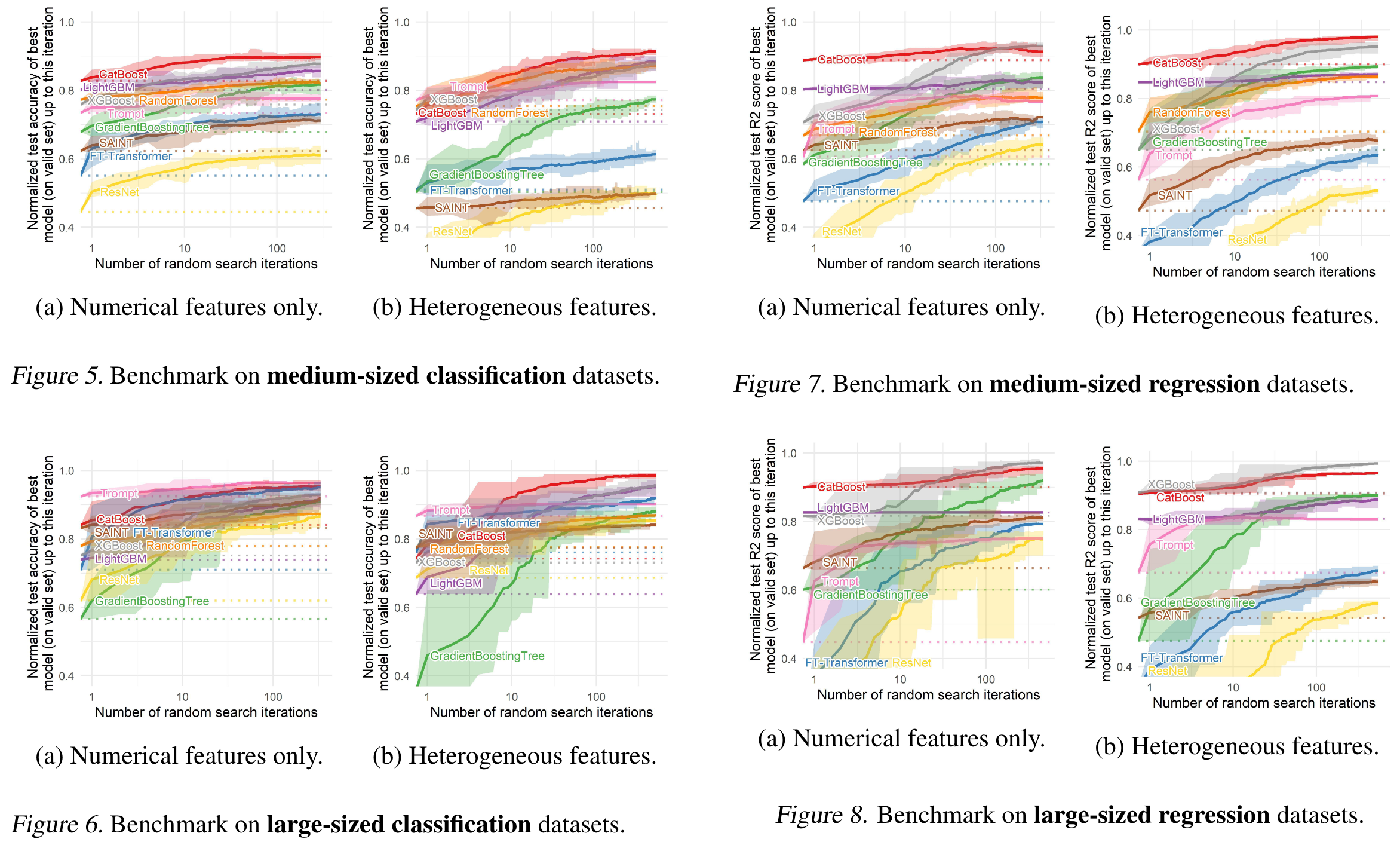
HPO comparison of performance grouped by task type (classification/regression) and dataset type (numerical only/heterogeneous).
Classification on medium datasets
Trompt outperforms DL baselines.
Also gets closer to tree-based models' performance.
Classification on large datasets
Less clear performance difference between DL and tree-based models.
Trompt shows very strong performance on numerical features.
also comparable to FTT on heterogeneous features.
Regression on medium datasets
Outperforms other DL methods.
Gets closer to tree-based, but not quite.
Regression on large datasets
Slightly below FTT and SAINT on numerical features.
But very large gap on heterogeneous features.
HPO Ablation
Having a larger prompt doesn't always help (default at 128 seems good enough).
Transforming the feature embeddings with a dense layer is crucial.
If we don't do this, it means each prompt is looking at the same feature embeddings.
Trompt does learn meaningful feature importances.
Evaluated by testing against GBDTs on synthetic datasets.
Gorishniy, Yury, Ivan Rubachev, Valentin Khrulkov, and Artem Babenko. "Revisiting deep learning models for tabular data." Advances in Neural Information Processing Systems 34 (2021): 18932-18943.↩
Somepalli, Gowthami, Micah Goldblum, Avi Schwarzschild, C. Bayan Bruss, and Tom Goldstein. "Saint: Improved neural networks for tabular data via row attention and contrastive pre-training." arXiv preprint arXiv:2106.01342 (2021).↩
Grinsztajn, Léo, Edouard Oyallon, and Gaël Varoquaux. "Why do tree-based models still outperform deep learning on typical tabular data?." Advances in neural information processing systems 35 (2022): 507-520.↩