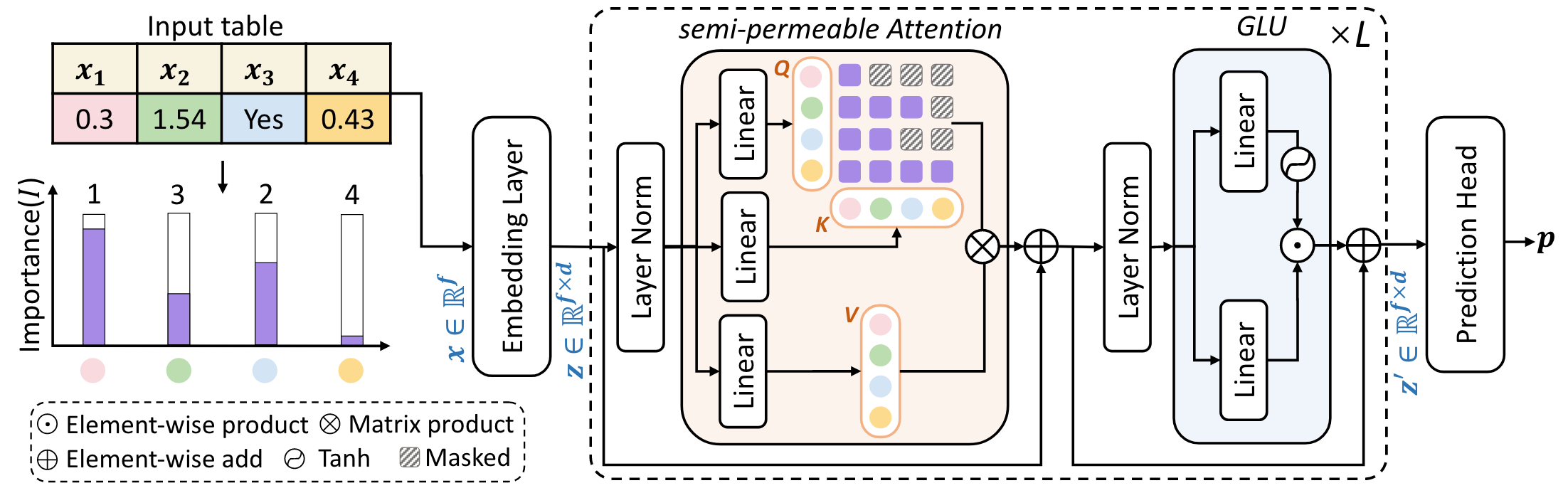
Deep learning on tabular data faces three challenges:
rotational variance -- the order of columns should not matter.
large data demand -- DNNs have a larger hypothesis space, and require more training data compared to shallow algorithms.
over-smooth solution -- DNNs tend to produce overly smooth solutions. i.e. when faced with irregular decision boundaries, the learning algorithms suffer (as pointed out by Grinsztajn et. al
Approach
Overview of aproach
3 main components: Semi-Permeable Attention, Interpolation-based data-augmentation(Feat-mix, HID-mix), and Attentive FFNs.
Semi-Permiable Attention
The authors propose to add a mask to the attention score matrix such that the less important features do not influence more important features, but the more important features can influence the less important features.
$$
z' = \text{softmax}(\cfrac{(z W_q) (z W_k)^T \underline{\oplus M}}{\sqrt{d}}) (z W_v)
$$
where \(\oplus\) denotes element-wise addition and \(\oplus M\) is the proposed change to vanilla MHSA. \(M \in \mathbb{R}^{f \times f}\) is a fixed mask, where
where \(I(\bf{f}_i)\) is the importance of the \(i\)-th feature. In other words, this terms means that less informative features may use information from more informative features (case 0), but the opposite is blocked.
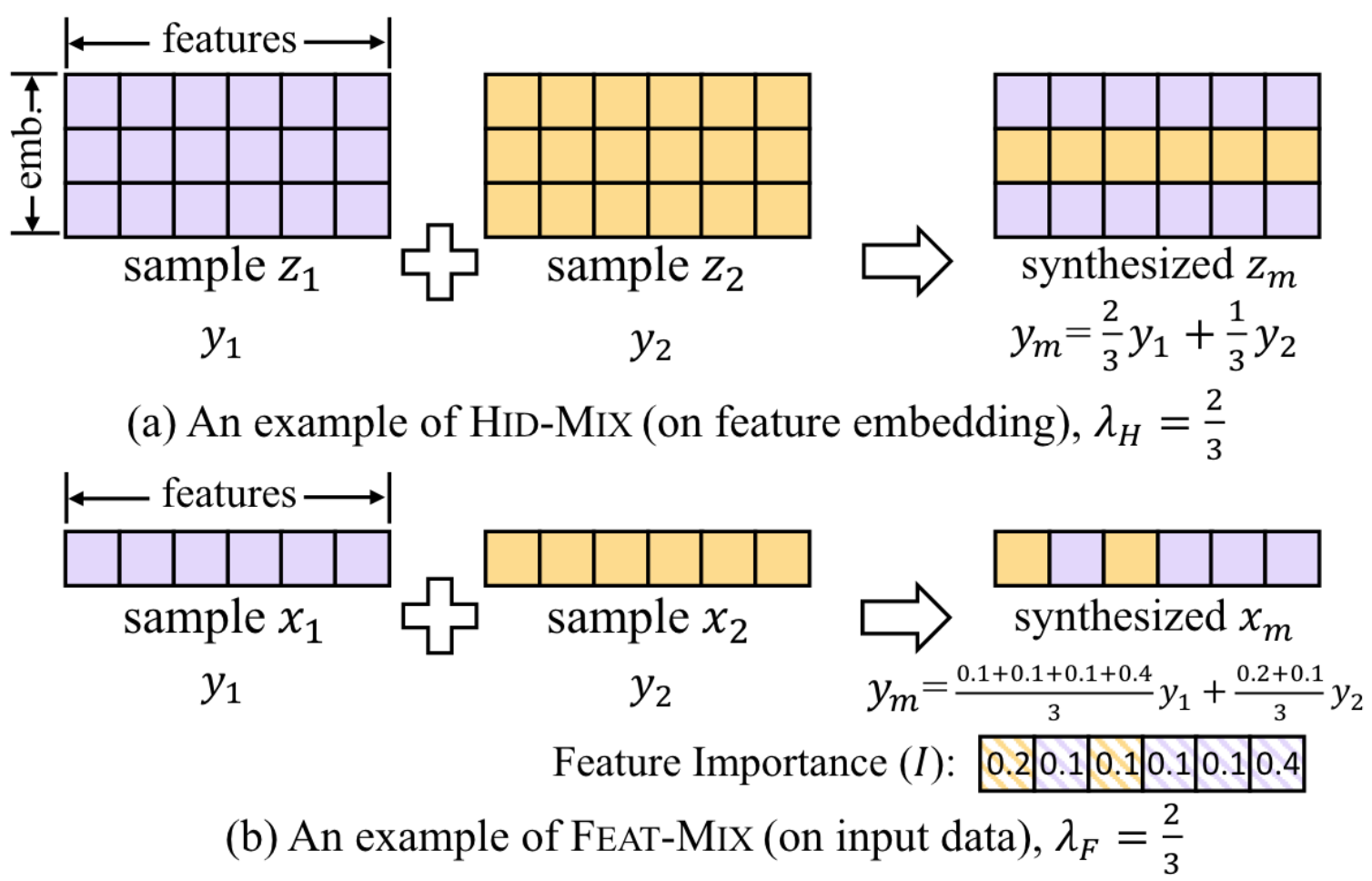
Interpolation-based data-augmentation
Illustration of HID and FEAT mix
HID-mix operates on the embedding level, while FEAT-mix operates on the feature level.
HID-mix
Given two samples \(z_1^{(0)}, z_2^{(0)} \in \mathbb{R}^{f \times d}\) and their labels \(y_1, y_2\), a new sample can be formed by mixing the embedding dimensions of \(z_1^{(0)}\) and \(z_2^{(0)}\):
where \(S_H \in \{0,1\}^{f \times d}\) is a stack of binary masks \(s_h\), \(S_H = [s_h, s_h,..., s_h ]^T\), where \(\sum s_h = \floor{\lambda_H \cdot d}\) for each row vector \(s_h\), and \(\mathbb{1}\) is a \(f \times d\) matrix of \(1\)s. In other words, \(S_H\) masks out \(\floor{\lambda_H \cdot d}\) entries of each row.
Intuition
Since each embedding element is projected from a scalar feature value, we can consider each embedding dimension as a distinct "profile" version of input data. Thus, Hid-Mix regularizes the classifier to behave like a bagging predictor.
FEAT-mix
Instead of mixing the embedding, FEAT-mix mixes the features given two samples \(x_1, x_2 \in \mathbb{R}^{f}\) and their labels \(y_1, y_2\), a new sample can be formed by mixing the features of \(x_1\) and \(x_2\):
where \(s_F \in \{0,1\}^{f}\) is a binary mask vector where \(\sum s_F = \floor{\lambda_F \cdot f}\), \(\mathbb{1}_F\) is a \(f\) dimensional vector of \(1\)s, and \(\Lambda\) is a scalar.
If we set \(\Lambda = \lambda_F\), this equivalent to cutmix1.
To differentiate, the authors introduce the usage of feature importance in the label weighting as follows:
where \(s_F^{(i)}\) is the \(i\)-th element of \(s_F\), and \(I(\bf{f}_i)\) is the importance of the \(i\)-th feature. Similarly to the SPA module, the mutual information is what the authors appear to use.
Intuition
Since each feature may have different contribution to the label, weighing the two labels by how much "usefulness" each sample contributed allows uninformative features to be filtered.
Attentive FFNs
Finally, the authors propose to replace the 2-layer FFN module at the end of the transformer block with a 2-layer Gated Linear Unit (GLU) module instead, like the following:
where \(\odot\) is element-wise multiplication and the first term acts as the gate.
In addition, the authors replace the linear embedding layer with similar GLU setup as well, which used to be \(z_i = \bf{f}_i W_{i,1} + b_{i,1}\), into \(z_i = \text{tanh}(\bf{f}_i W_{i,1} + b_{i,1}) \odot \bf{f}_i W_{i,2} + b_{i,2}\).
However, why they do this is not very clearly motivated.
Findings
Excelformer works well on both small and large datasets!
While other models need HPO to be competitive, Excelformer is competitive without HPO.
Yun, Sangdoo, Dongyoon Han, Seong Joon Oh, Sanghyuk Chun, Junsuk Choe, and Youngjoon Yoo. "Cutmix: Regularization strategy to train strong classifiers with localizable features." In Proceedings of the IEEE/CVF international conference on computer vision, pp. 6023-6032. 2019.↩