In-Context Data Distillation with TabPFN
Summary
This paper explores applying data distillation for the context data for TabPFN. The authors also draw a comparison of this process to prompt-tuning -- where the "prompt" is optimized for a particular task.
Approach
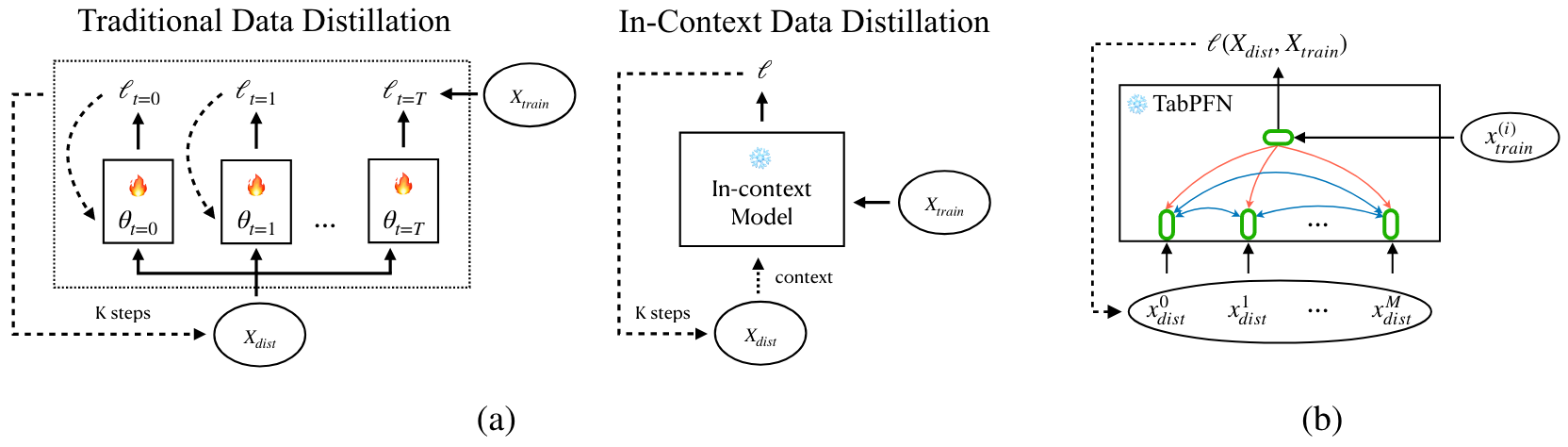
Comparison of traditional data distillation (DD) and in-context data distillation (ICD) for TabPFN.
Minimize the following to maximize the likelihood of $\mathcal{D}{\text{train}}$ given \(\mathcal{D}_{\text{distill}}\)_:
\(\nabla_{\mathcal{D}}\mathcal{L}(\mathcal{D}_{\text{train}} \rightarrow \mathcal{D}_{\text{distill}})\), the gradient for \(\mathcal{D}_{\text{distill}}\), can be directly computed instead of proxy-training like previous data distillation works because TabPFN's inference step mimics the traditional training procedure, meaning that we don't have to train the target model for each distillation iteration. In traditional data distillation, the target model is trained for \(T\) iterations before \(\mathcal{D}_{\text{distill}}\) is updated once.
Findings
TabPFN: sample 1,000 random points from \(\mathcal{D}_{\text{train}}\) to use as \(\mathcal{D}_{\text{context}}\). TabPFN-ICD: Distill \(\mathcal{D}_{\text{distill}}\) with 1,000 samples from \(\mathcal{D}_{\text{train}}\) and use as \(\mathcal{D}_{\text{train}}\). Datasets: From Tabzilla, but only use ones with more than 2,000 samples.
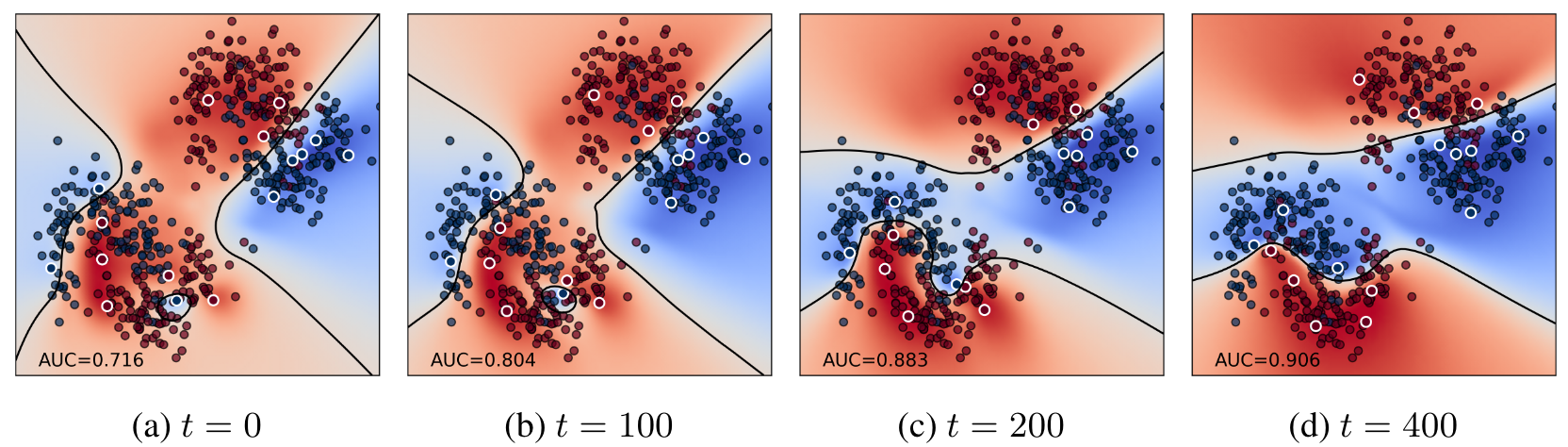
Evolution of the distilled points.
- dots with white outline: distilled points.
- dots with black outline: test points.
- shade (red/blue): predicted label.
- black line: decision boundary where \(p(y|x, \mathcal{D}_{\text{distill}}) = 0.5\).
- TabPFN's performance (comparative to XGB) drops as a function of the number of samples.
- Applying data distillation to get the context data actually improves performance.